Hello,
This is a long post but you can safely skip to the TL;DR if you don't need any background information. I'm quite new to YAWL and the more I'm getting my hands dirty with YAWL the more I'm thinking I could've more easily stuck to PNML and WoPeD, it's as though I just installed a z10 mainframe even though a supermicro would've sufficed. Or a fully featured install of MSSQL even though all I need is Sqlite. What drove me away from that idea though is the price tag on the pnml specification, can't guarantee interoperability without access to the spec.
The task at hand is to create a fully-automated data-driven flow, a lot of data goes in, some data comes out. As I originially devised it, there would be one big petrinet which is evaluated whenever a timer fires a "tick" function. This would do several things:
* Store the current time
* Evaluate the net
* Fire any triggered transitions
The transitions could evaluate and sort data or perform a task such as raising a flag. Another approach would use runs instead of ticks; the system would consist of a vastitude of small nets and they'd all have to complete before their share of time runs out (or an exception is raised). Most of them would be similar to attached image, it's basically mapping a rule-based system to workflows. Which is why I don't think anyone is going to bother adjusting anything, since it probably becomes error-prone sooner than later. I'd be better of simply writing them as stored procedures in the RDBMS and invoking those on a schedule, waiving the benefits of a WFMS such as being able to run simulations.
Writing Java is no problem. It's a really nice language and if the alternative is writing WS-Deathstar services, thanks but no thanks.
TL;DR: Has anyone augmented their DBMS with YAWL as a WFMS or would you consider this to be a (near-)perfect use case for YAWL?
Best wishes.
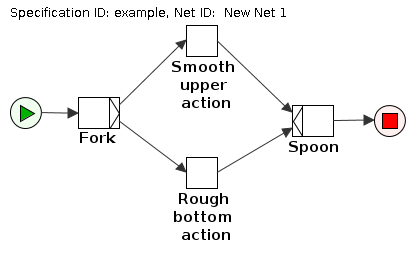
I changed the upload field to
I changed the upload field to a different image but somehow the old image was attached instead. My bad, here's a more appropriate image.
Hello,
Hello,
I must admit, that I do not fully understand your use case, but I will try to say something.
YAWL has the three perspectives control flow, data and resources. It is best when the three are needed.
If you have purely data driven and fully automatic workflows you might have a look at WMS for scientific workflows like Taverna or Kepler.
Regards
Thank you for your answer.
Thank you for your answer. The example flow was merely what would happen if the system would run to completion every time it's ran. This is not the model used by most systems and the example merely serves as an illustration to explain why.
No users are going to log into YAWL and there's no work to be assigned to any agent except to automated ones (i.e. computer programs). So, yes, any data would be kept inside an RDBMS which complements the WMS (and vice versa).
I've tried adding custom codelets but I couldn't get them to appear in the editor, that and getting it to work on Scientific Linux using Tomcat (and Apache httpd) was a bit painful. Using MS-Windows isn't an option, so no YAWL4Enterprise. This is unfortunate, but I'm very happy with your suggestions. Particularly Taverna which I'll be sure to have a look at.
Regards